Exploring GPT-4 Functions: Enhancing Interactivity in Chat Applications

Earlier this year at Falck, we embarked on an exciting journey of integrating GPT models into our solutions. We developed a suite of innovative solutions including Falck GPT, AskPDF, Meeting Summarization, and Document Translations using Microsoft Power Platform. With the recent advent of copilots, it's become crucial for us to stay abreast of the latest capabilities to empower our coworkers to work more effectively.
Our existing chat functionality, which operates in a manner similar to the original Chat GPT, is currently limited to providing a simple text input and receiving a text response. We aimed to enhance Falck GPT's capabilities by enabling it to perform actions for the user, rather than merely providing instructions. By leveraging GPT 3.5 and GPT 4 models, we've gained access to a feature called 'functions'. These can be thought of as a list of actions that the model can execute based on a defined description.
In this article, we'll guide you through the implementation of these functions, specifically focusing on empowering our colleagues to generate images using this feature.
Example of a function
Consider a scenario where we create a new function that enables sending an email with the content of the last message. The GPT model processes your query and checks for any relevant functions. If a relevant function exists, it informs you that the user intends to execute the function 'send an email with the last response', which you had previously defined. It also provides you with the schema that you used in the definition.
At this point, the process for the model concludes. GPT has relayed that the user intends to execute an action, provided us with the precise schema for the expected input, and indicated which action should be executed. We now need to implement our logic. This could involve actions as simple as sending an email, sending an HTTP request to fetch details from another system, booking a flight, reserve a hotel room, and so on. This is where we step in to manage these functions.
In our example, where the goal is to send a simple email to the user, we could utilize Power Automate to send it and then inform the model that an email has been dispatched. The model can then respond to the user. You might wonder why we need to reply to the model instead of the user directly. While it might not always be necessary, typically, you will process the request and receive some data. For instance, if you're booking a holiday, you might receive a 200 HTTP status code along with some information that should be processed by the model before it's returned to the user.
This provides a high-level overview of what functions are and how they can be utilized. There are numerous ways to implement them. In the following guide, we'll be using Power Automate, as that's the integration we previously built for Falck GPT to call the Azure Open AI endpoint for processing user queries. Naturally, the process would be similar if you opted to use an Azure function or any other option you might be more familiar with.
Current implementation
As it stands, we employ a simple Power Automate flow to process the requests. On the front-end, we have a canvas application with a chat interface. We use a gallery for the history, and for text input, we've built a custom PCF component that enables users to submit their messages by pressing 'Enter'—a feature that was initially the most requested change to the application.
When a user sends a message, depending on the selected settings, a temperature value (0, 0.7, or 1) will be set, and a model (GPT 3.5 or GPT 4) will be chosen. While there are numerous side processes that occur (such as saving conversations in history, which runs in the background), this article will solely focus on the chat aspect. Upon pressing 'Enter', the flow is triggered with the following arguments: model, temperature, and content.
The content includes the entire conversation that the user has had up to that point, along with the latest question. We simply pass this information in the HTTP request to the endpoint, await the response, and relay it back to the user. At one point, we considered introducing response streaming (we even built a custom PCF component that worked). However, due to the way galleries are refreshed in Power Apps, the experience wasn't as seamless as we'd hoped. For now, we're sticking with Power Automate.
Once the model provides a response, one of two scenarios will occur:
- We receive the response, extract it from the body, and return it as text to the user.
- The action fails due to the content filter policy. In this case, we extract the reason for the failure and inform the user that they need to try again or initiate a new conversation.
In essence, the main application serves as a simple wrapper around the GPT endpoint.
What we would like to achieve
Now, we arrive at the exciting part. We aim to extend the functionality of our main application, Falck GPT, by incorporating functions. We already have many innovative ideas in the pipeline, such as interacting with company data, generating images as can be done in Bing chat or Chat GPT, automating holiday reservations, or simplifying the process of registering a request in our internal ticket application. The potential applications for this are limitless, particularly as we continue to transition away from traditional user interfaces and increasingly adopt co-pilots, enabling data interaction through chat.
Once we upgrade the flow that processes the logic to call the endpoint and construct it in a scalable manner, we'll be able to add an unlimited number of functions easily. It will be as straightforward as sending an HTTP request to any of our other systems and then processing the data uniformly.
For this article, and as one of our initial implementations, we're going to focus on image generation. You might wonder why? Well, aside from being a cool feature, it's also highly requested by many of our users who are already using it in Chat GPT (which is great for storing conversations, but poses a risk of accidental company data leaks) and Bing Chat (which is secure as we use the enterprise version, but doesn't store conversations, run functions, or allow further extensions). Hence, we deemed it a fitting choice for the first official function addon to our Falck GPT solution.
Let's get started
Firstly, we'll need to make some adjustments to our flow. To enable functions, we need to update the API version to 2023-07-01-preview. This is a significant upgrade as it allows us to pinpoint the reason why a content filter policy was applied. Unlike before when it simply blocked content, it now specifies the exact reason. While this is a beneficial change, it does alter the response schema slightly, necessitating an update to our ParseJSON schema.

Naturally, this also implies that we need to revise the logic where we respond to the user. Rather than providing a generic message stating that the message is invalid, we can pinpoint the reason (such as hate speech, etc.) and provide comprehensive details. This allows users to reframe their question or further tailor their prompt. Unfortunately, this is the most challenging aspect for me to test. When I attempt to trigger the filter policy myself, it invariably returns a simple message, "I can't assist you with that". However, for other users, the endpoint simply fails and returns the content filter policy error message.
We hope that this version of the endpoint will facilitate easier validation. With that resolved, we can now shift our focus to the main part: implementing the actual function calling.
At this point, I propose dividing the tasks into three parts:
- How do we process the response when the model intends to call a function or simply return a message to the user?
- What mechanism could we employ to confirm functions? We wouldn't want to execute actions on the user's behalf in case the model has erred in its judgment and incorrectly decided on the function.
- How do we process the response to the user when the model has determined that a function needs to be called, and the user has confirmed their intention to execute it?
For confirmations, the logic should be relatively straightforward - we implement a simple flag for each of the functions to determine whether user confirmation is required, or if it's safe enough to process without it. For instance, in the case of image generation, there's no harm in creating an extra image for the user. However, if we're considering inserting a new account record into our sales CRM system, we need to ensure that the user indeed intended to execute this action.
To implement this flag, we need to carry out two steps: add a new argument in the flow trigger, and utilize that within the HTTP request.

We could include the flag directly in the body of the request. However, I've observed that sometimes, before users reload the application, they send requests without the property. For this reason, I'll initially set the field as optional and process blank values in the flow, defaulting it to 'none'. This means that functions will be turned off by default.

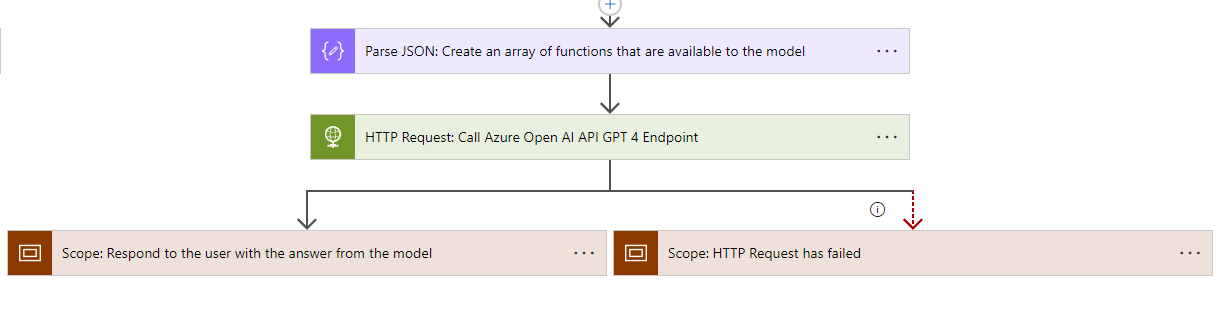
Returning the response is relatively straightforward. If we receive a simple response from the model, we'll respond to the user and terminate the flow. Conversely, when a function needs to be executed, we'll check for the confirmation flag.
- If no user confirmation is required, we'll execute the function, call the model again with the function's response, and provide the user with the output of the request.
- If user confirmation is needed, we'll respond to the application with the confirmation information and terminate the flow. When the user on the front end confirms the function call by pressing the button, we'll trigger the same flow again. However, this time, we'll skip the initial call to the model by providing another argument and proceed directly to the function execution.
Defining Available Functions
Defining Available Functions: It's crucial to define all the functions that we can pass to the model. In the long run, it would be more efficient to store them in a Dataverse table rather than hardcoding them in the flow. This approach would enable admin users to activate or deactivate functions on the fly and also introduce RLS (Row-level security) for functions.
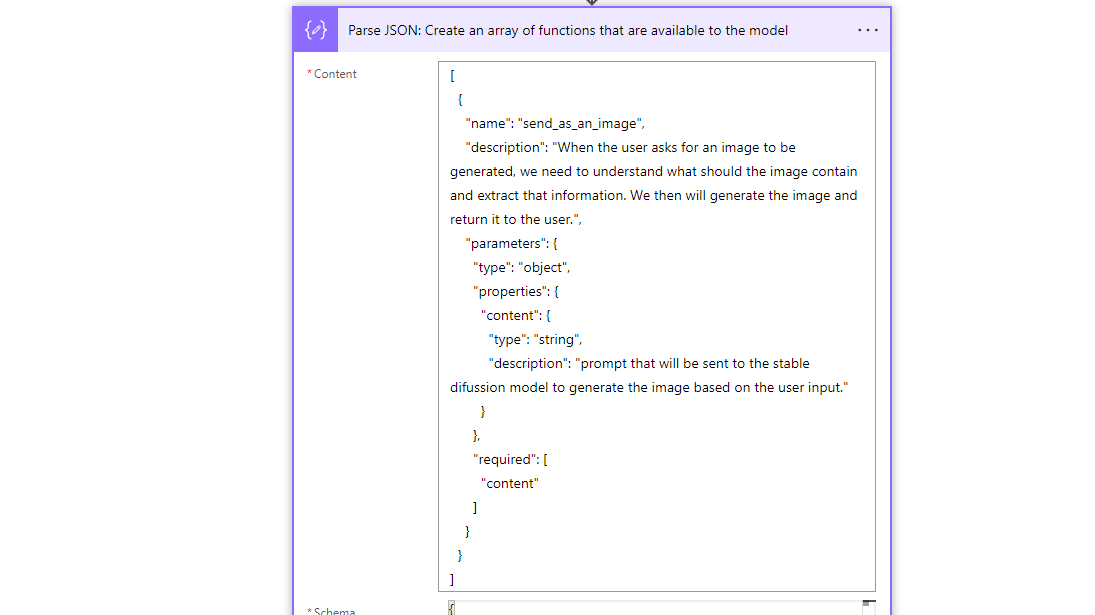
For the time being, we'll create a simple array to establish the functions. Our initial goal is to test the capabilities of the functions and assess how easily they can be integrated. Once we've done that, we'll proceed to clean up the code. Naturally, after creating the array, we'll include it in the request body for the request.
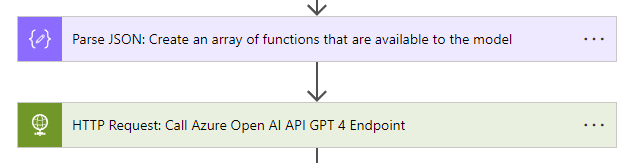
Of course, the actual body of the request must contain functions. Otherwise, the request will fail, as functions must be included when the 'function_call' property is set.

Excellent! We've now created the first function, incorporated it into the HTTP call, and modified the response schema to include the function response and the new content filter policy breakdown. This will enable us to identify which filters triggered the response filtering. Consequently, users can better understand the reasoning behind it and tailor their questions to avoid such filtering in the future.
Processing the Response
The subsequent steps involve introducing a method to handle functions after the request has succeeded. In the long term, we plan to move the logic outside of Power Automate, as handling it in another language, such as Python, would be much easier. However, for now, to facilitate quick testing and validation of new functions, we'll build everything in Power Automate. This approach also enables those who focus solely on low-code to implement the same functionality without the need to learn other languages.
Once we've utilized the Parse JSON action to process the model response, we'll implement a switch statement. For the item itself, we'll select the name property of the function call.
body('Parse_JSON:_Process_Model_Response')?['choices']?[0]['message']?['function_call']?['name']
For now, there will only be two cases: the function for image generation, and the default one. The default case will simply execute the remainder of the flow or return a response to the user if no function was invoked.
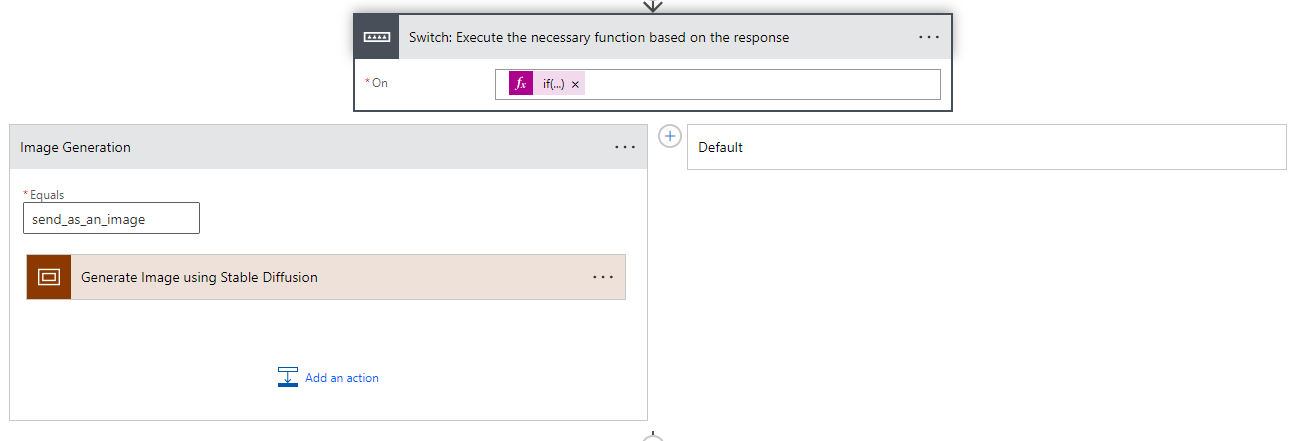
Within the scope, we need to perform the following actions:
- Extract the arguments as JSON for easier access.
- Send an HTTP request to generate the image.
- Create the generated image in a blob container.
- Append the initial response generated by the model to the messages array.
- Include the new response from the function, which in our case is the URL to the image.
- Send another request to the GPT endpoint with the URL.
- Respond to the user with the resulting text.
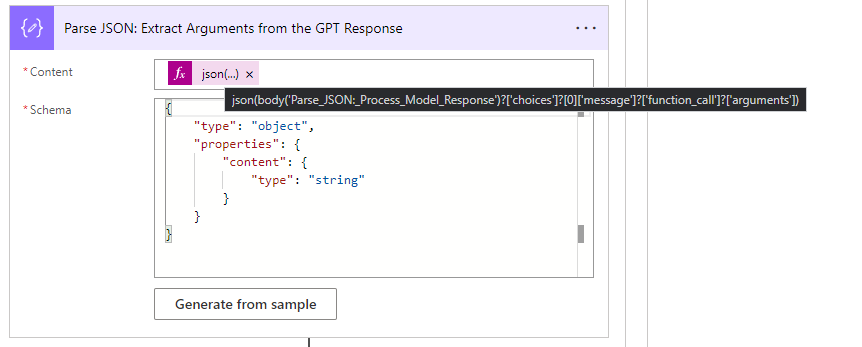
The first step is straightforward and not a requirement. I adopt this approach as it enhances readability and aids in error handling when incorrect values have been received. The 'arguments' property is a stringified version of JSON that encompasses all the parameters you've defined in the function definition earlier. Since we can't use a text version, particularly in cases where we have more than one parameter, we employ the Parse JSON action for direct access.
{
"input_data": {
"columns": [
"prompt"
],
"data": [
body('Parse_JSON:_Extract_Arguments_from_the_GPT_Response')?['content']
],
"index": [
0
]
}
}
With the content now easily accessible, we need to call the endpoint responsible for image generation. At this stage, we'll only pass the prompt itself and nothing else. We can achieve this by including the content, which we previously received from the GPT response, in the data array. With all these steps completed, we're now ready to send a request.

The response you're likely to receive should resemble the following:
{"prompt":"ambulance helping a patient","generated_image":"base64oftheimage","nsfw_content_detected":null}
We can now utilize this information to create the image in the blob container. The creation of containers and the use of blob storage fall outside the scope of this article, so please review the process of creating one afterward. For now, we'll employ the out-of-the-box action called 'Create blob v2'.
Here, we'll need to set up a few inputs:
- Storage account: This is the name of the storage account.
- Folder path: This is the container where you'd like to store the images.
- Blob name: This is the filename. We'll use concat(guid(), '.png') for this.
- Blob content: We need to convert the base 64 content to binary.
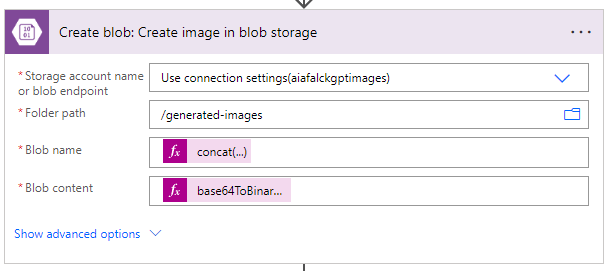
Here's also the code we use for the blob name and content:
Blob name: concat(guid(), '.png')
Blob content: base64ToBinary(body('HTTP:_Generate_Base_64_of_an_image')[0] ['generated_image'])
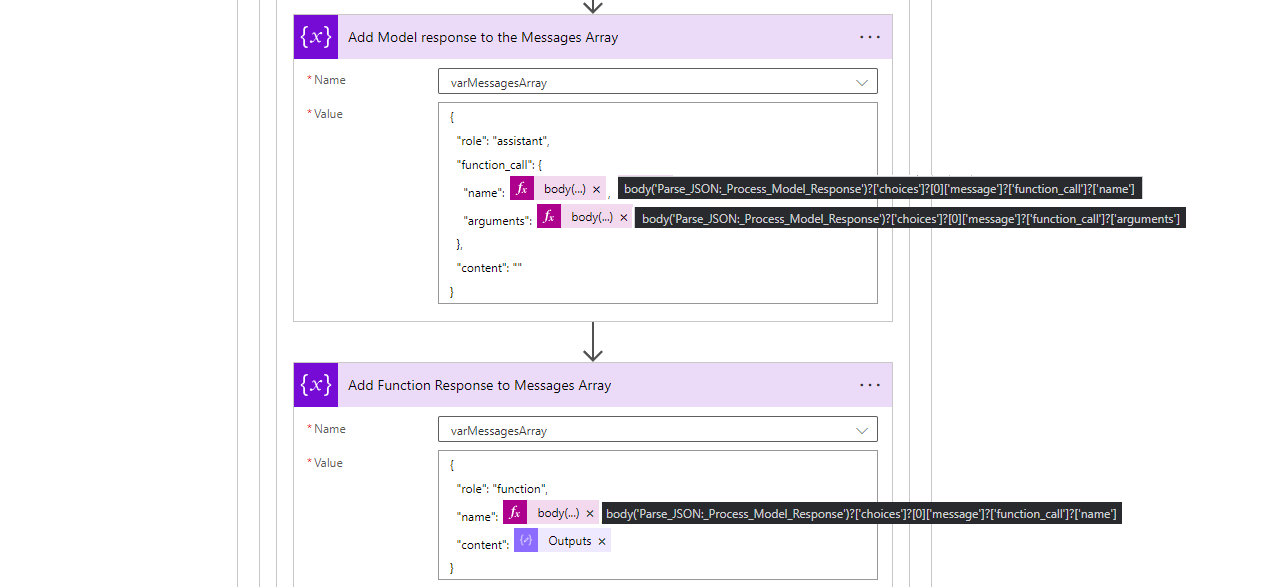
Having retrieved the response, generated the image content, and created the file in the blob storage, we've now completed the main function. Our remaining task is to add the original response and the function response to the messages array. This allows the model to retain the context of the prompt used in the generation, enabling users to reprompt the model if the photo doesn't meet their expectations.
After adding them to the messages array, we're now ready to send a final request to the GPT endpoint to process the user's question based on the function's answer. In our scenario, we could also return the image directly. However, with our plan to standardize and streamline the response process across all functions, it would be much more efficient to simply recall the model.

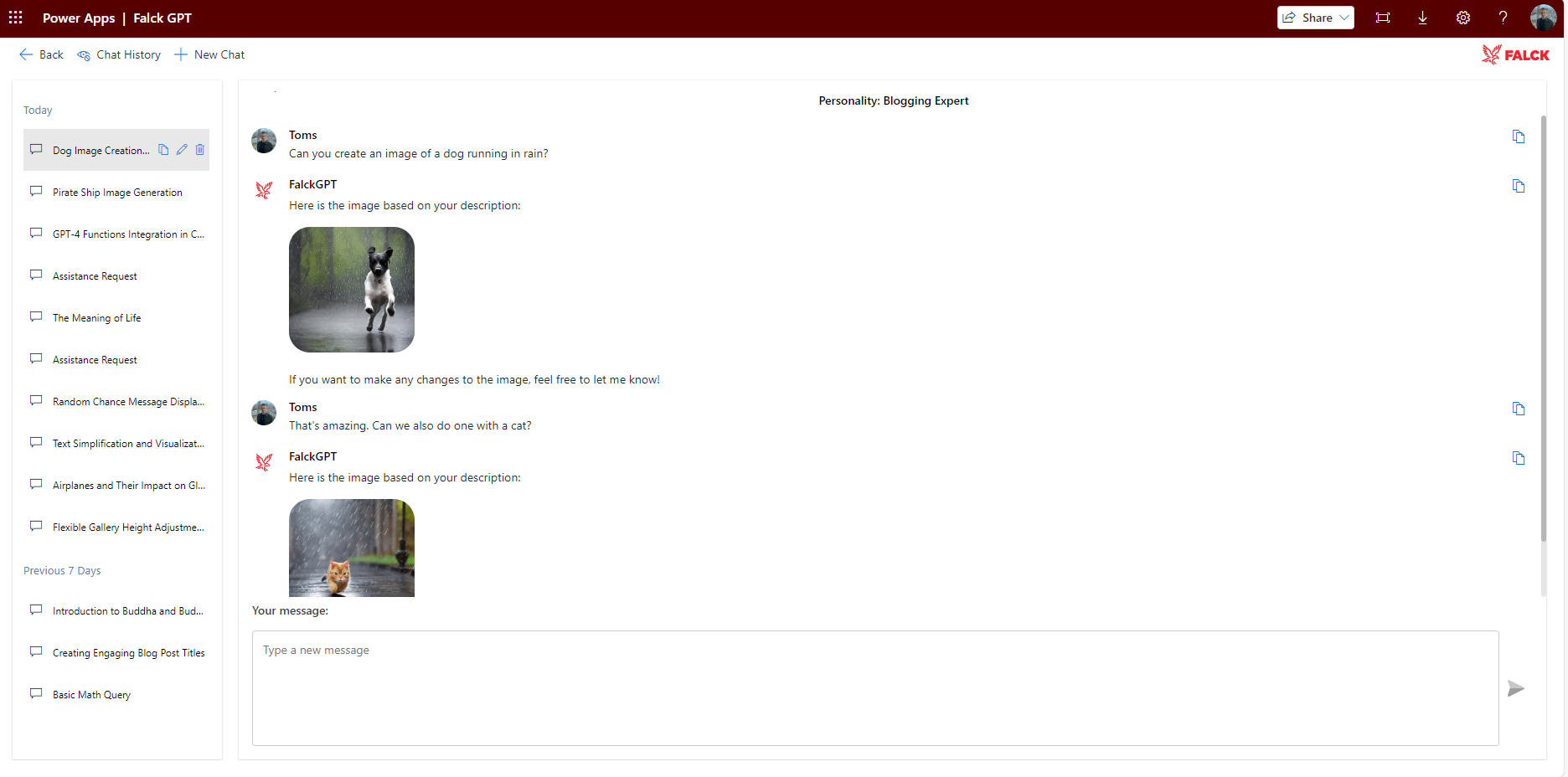
Let's Test the Model
In full disclosure, I attempted to generate this exact image three times as it wasn't producing the result I was aiming for. After the third attempt, it achieved the exact look I desired. This was accomplished by asking the model what prompt it had used previously, which it was aware of since we included it in the messages array, and requesting it to make some modifications.
If you have any further questions or need any clarifications about integrating GPT models into your solutions, or about the implementation of functions, don't hesitate to leave a comment below or reach out to us by email. We're here to help you navigate this exciting new frontier in chat application functionality! 😎

Comments ()